Integer division is expensive. Much more expensive than multiplication. Much, much more expensive than addition. If you’re trying to make some integer operations really fast it’s bad news if you need to do division.
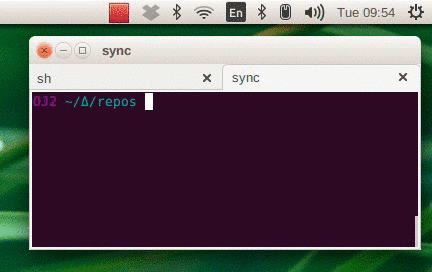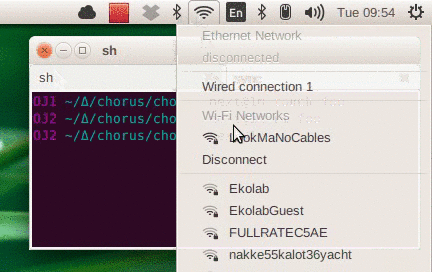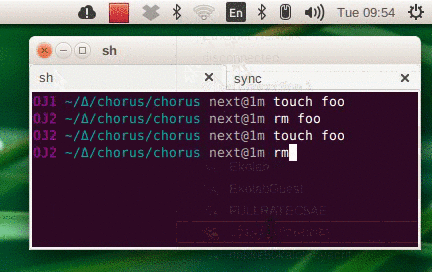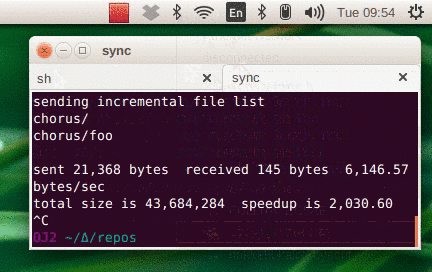
A while ago, for a hobby project, I happened to be playing around with variable-length integer encodings. Where you store integers such that small ones take up less space than large ones. This is the kind of thing you want to be very fast indeed. At one point I ended up with this expression on a hot code path:
(63 - nlz) / 7For everything else I could come up with fast ways of doing it using bitwise operations but this one place I ended up with division. And in this case not only is it expensive it’s overkill: the value we’re dividing by is a constant and in this case nlz is known to be between 0 and 63.
I thought: I’ll experiment a bit and see if I can’t come up with some bitwise operations that work just like dividing by 7 when the input is between 0 and 63. The one kind of division that is very cheap is by a power of 2, that’s just bit shifting. And it happens to be the case that 7 * 9 = 63, which is almost 64, a power of 2. Putting those together I got something I thought might do the trick:

This you can compute with bitwise operations!
(9 * v) / 64
= (9 * v) >> 6
= (v + 8 * v) >> 6
= (v + (v << 3)) >> 6Not bad! An expression that is purely bitwise operations but that computes almost division by 7. How “almost”? It turns out that this works for 0 to 6 but gives the wrong answer for 7: it yields 0 where it should be 1. Okay, it’s off by 1 — let’s try adding 1 then:
(v + (v << 3) + 1) >> 6Now it’s correct from 0 to 13 but gives the wrong answer for 14: 1 where it should be 2. So let’s try adding 2 instead of 1. That makes it works for 0 to 20. If we keep increasing the fudge factor as long as we keep getting the right answer we end up with:
(v + (v << 3) + 9) >> 6This computes v / 7 correctly for v from 0 to 69 which was what I needed originally. Actually I only needed up to 63.
Excellent! Problem solved! So let’s get back to varint encoding? Well, now I was on my way down the rabbit hole of bitwise division. What if it wasn’t 7 I needed to divide by, could I do something similar for other values? Where did the limit of 69 come from, and the fudge factor of 9?
Let’s generalize
A quick recap: because 7 * 9 = 64 - 1 we can implement v / 7 like this:
(9 * v + 9) / 64
= (v + (v << 3) + 9) >> 6for v between 0 and 69.
Put more abstractly: given a divisor d, which happened to be 7, we found a power of 2, 64 = 26, such that

for a multiplier value m which in this case was 9.
Using this together with a fudge factor a which also turned out to be 9, we were able to replace division by d with
(m * v + a) >> nwhich gives the correct result for values between 0 and some limit L, where L in this case was 69.
Now, what if I wanted to divide by some other value than 7? Let’s say 43? Then we have to find an n such that

for some m. That just means an n such that 43 is a factor in 2n-1. I’ve put a table of the prime factors of 2n-1s at the bottom. There is one: 214-1.

So you can replace v / 43 with
(381 * v + a) >> 14
for some choice of a, and then it will be correct for values up to some limit L. What should a be and what will that make L? Well, let’s try to derive them. Let’s start with a. (And just skip the derivations if this kind of stuff bores you).
One thing that definitely must hold is that if you bitwise-divide 0 by d the result must be 0:
(m * 0 + a) >> n = 0


So we know that definitely the fudge factor must be non-negative. Similarly if you bitwise-divide d-1 by d the result must also be 0; that gives us:
(m * (d - 1) + a) >> n = 0m + a}{2^n}}\right\rfloor = 0")
m + a < 2^n")




Putting those two together we get that

But which a to choose? There we can use the fact that bitwise division increases more slowly then real division so when it gets the answer wrong, it’ll be because it returns too small a value. So we want a to be the largest allowed value: m.
Next, let’s derive L. Or, let’s derive L+1, the first value where bitwise division yields the wrong result. Since bitwise division grows more slowly than division that will be at some multiple of d, k d, where it yields a value less than the true result: k – 1.
(m * k * d + m) >> n = k - 1
 \le m k d + m < 2^nk")
 \le (2^n-1)k + m < 2^nk")
 \le 2^nk - k + m < 2^nk")


The smallest k which yields a wrong result is hence the first value greater than m: m + 1 so that makes L:
L + 1 = k * d
L + 1 = (m + 1) * d
L = (m + 1) * d - 1Just to verify let’s try the example from before: 7
L = (9 + 1) * 7 - 1
= 69Another useful way to write this is
L = (m + 1) * d - 1
= (m * d) + d - 1
= 2n - 1 + d - 1
= 2n + (d - 2)This means that for any d > 2 L is at least 2n. That gives a nice rule of thumb: the bitwise division by 43 above holds for all values up to 214. And then a bit more.
Can you always find a value of n that lets you do bitwise division? In theory probably yes, I’m not good enough at number theory to say definitively. But since in practice we’re working with finite numbers you usually want n to be less than 32 and then the answer, at least initially, is no. Here are some values that you can’t bitwise divide with an n at most 32:
37, 53, 59, 61, 67, 71, 79, 83, 97
Does that mean that if we end up having to divide by 37 there is no way to express that as a bitwise operation? No. This exact approach doesn’t work but there are others. For instance, so far we’ve only looked at dm = 2n-1. There’s also dm = 2n+1 — maybe we can use that when 2n-1 doesn’t work? (Spoiler: yes we can, not always but often). What about dm = 2n-2, might that be useful somehow? There’s more fun to be had with this. But that’s for another post.
Appendix
Prime factors of 2n – 1 for n up to 32 (Mersenne primes marked in bold).
| n | prime factors of 2n – 1 |
| 2 | 3 |
| 3 | 7 |
| 4 | 3, 5 |
| 5 | 31 |
| 6 | 3, 3, 7 |
| 7 | 127 |
| 8 | 3, 5, 17 |
| 9 | 7, 73 |
| 10 | 3, 11, 31 |
| 11 | 23, 89 |
| 12 | 3, 3, 5, 7, 13 |
| 13 | 8191 |
| 14 | 3, 43, 127 |
| 15 | 7, 31, 151 |
| 16 | 3, 5, 17, 257 |
| 17 | 131071 |
| 18 | 3, 3, 3, 7, 19, 73 |
| 19 | 524287 |
| 20 | 3, 5, 5, 11, 31, 41 |
| 21 | 7, 7, 127, 337 |
| 22 | 3, 23, 89, 683 |
| 23 | 47, 178481 |
| 24 | 3, 3, 5, 7, 13, 17, 241 |
| 25 | 31, 601, 1801 |
| 26 | 3, 2731, 8191 |
| 27 | 7, 73, 262657 |
| 28 | 3, 5, 29, 43, 113, 127 |
| 29 | 233, 1103, 2089 |
| 30 | 3, 3, 7, 11, 31, 151, 331 |
| 31 | 2147483647 |
| 32 | 3, 5, 17, 257, 65537 |
Reverse index: for a prime, which 2n-1s is it a factor of:
| p | n where p is a prime factor of 2n-1 |
| 3 | 2, 4, 6, 6, 8, 10, 12, 12, 14, 16, 18, 18, 18, 20, 22, 24, 24, 26, 28, 30, 30, 32 |
| 5 | 4, 8, 12, 16, 20, 20, 24, 28, 32 |
| 7 | 3, 6, 9, 12, 15, 18, 21, 21, 24, 27, 30 |
| 11 | 10, 20, 30 |
| 13 | 12, 24 |
| 17 | 8, 16, 24, 32 |
| 19 | 18 |
| 23 | 11, 22 |
| 29 | 28 |
| 31 | 5, 10, 15, 20, 25, 30 |
| 41 | 20 |
| 43 | 14, 28 |
| 47 | 23 |
| 73 | 9, 18, 27 |
| 89 | 11, 22 |
| 113 | 28 |
| 127 | 7, 14, 21, 28 |
| 151 | 15, 30 |
| 233 | 29 |
| 241 | 24 |
| 257 | 16, 32 |
| 331 | 30 |
| 337 | 21 |
| 601 | 25 |
| 683 | 22 |
| 1103 | 29 |
| 1801 | 25 |
| 2089 | 29 |
| 2731 | 26 |
| 8191 | 13, 26 |
| 65537 | 32 |
| 131071 | 17 |
| 178481 | 23 |
| 262657 | 27 |
| 524287 | 19 |
| 2147483647 | 31 |


















































 is the resulting temperature of the water,
is the resulting temperature of the water,  is the amount of boiling water which will be 100°,
is the amount of boiling water which will be 100°,  is the temperature of tap water, and
is the temperature of tap water, and  is the amount of tap water.)
is the amount of tap water.)}{700}")


 = 78 v_b")
 = v_b")
 = 8.97 \cdot 63 = 565")
 , the amount of tap water and some additional amount,
, the amount of tap water and some additional amount,  , to account for the pot,
, to account for the pot, }{v_b + v_t + v_p}")
 }{v_b + v_t + v_p}")
 }{700 + v_p}")



 }{700 + 103} = 76.9")
}{700 + 103}")


 = 78 v_b")
 = v_b")
 = 10.29 \cdot 63 = 648")
 . Boil that much water and pour it into the pot. Measure the temperature and call that
. Boil that much water and pour it into the pot. Measure the temperature and call that  . Measure the temperature of your tap water, call that
. Measure the temperature of your tap water, call that 
 (t_r-t_t)}{100-t_t}")
 & = & 0 \\ f(1) & = & 1 \\ f(2) & = & 4 \\ f(3) & = & 9 \\ & \vdots & \end{tabular}")




