Reload?
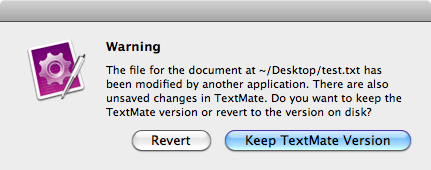
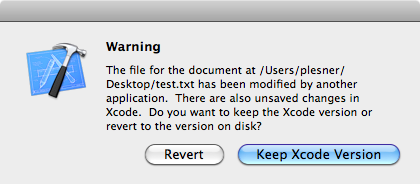
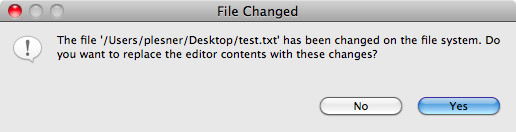
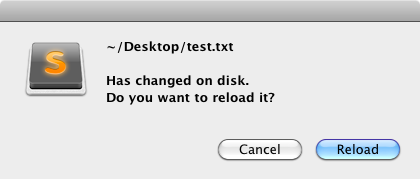
This post is about one of those messages you see every day of your life as a programmer, your editor telling telling you: this file has changed, would you like to reload or keep your changes? The problem with this particular message is that usually neither option is what you want. You’ve made changes to that file for a reason and you neither want to lose those changes or go out of sync with the file system. There’s a lot of new editors about these days (which is fantastic) but I’ve yet to see one make an attempt to solve this problem. This blog post gives some thoughts on how it could be solved.
The problem
![]()
The underlying issue here is that editors assume they have exclusive access to all files you are editing. Some editors including eclipse and emacs consider you to be editing a file as soon as you’ve opened it, before you’ve even made any changes. And once you have unsaved changes I don’t know of any editors that are forgiving if the file changes on disk in the meantime.
This assumption, that an editor can have exclusive access to a file, doesn’t seem sound. Just because you have a file open in an editor doesn’t mean it can’t change. If you’re working on a busy code base there could be people editing the same files as you at any time. Usually this is controlled through version control so you have control over when you sync and can make sure you don’t have unsaved changes when you do, but this is something you have to manage yourself. You get no help from your editor. Worse is if you’re working on something time critical, like configuration files that control a live application. These kinds of files can be very busy and you’ll want to both stay in sync and be able to queue up and submit changes quickly. In both cases, but especially the latter, the revert/override choice is really unhelpful.
And these problems is normal old-fashioned use of source code. Besides the emergence of new editors people are also busy working on web-based IDEs. This further undermines the assumption that an editor can own a file. As soon as you’re on the web it becomes much easier to share and collaborate. It may be desirable to support more fine-grained real-time collaboration in addition to the more coarse-grained version control model we’re used to, where modifications come in larger self-contained changesets. Real-time collaboration is not appropriate in many cases, but there are cases where it makes sense and it definitely shouldn’t be the capabilities of the editor that decides whether it’s feasible. If you want to use it the editor should support it, on the desktop or on the web.
Living source files
The good news is that this issue has long been solved in the context of collaborative online tools like google docs and google wave (I know there are loads of others but these are the ones I know best). These kinds of tools can’t assume that you have exclusive access to the document you’re editing, there can be any number of entities modifying a document at the same time. They also can’t assume that what you’re seeing is the current contents of the document. In fact in this setting the concept of an authoritative “current document” isn’t even well defined – as long as each participant keeps editing and their changes take a while to propagate the participants may all see slightly different versions of the document, none of which is more authoritative than the others. Only once everyone has stopped editing and everyone has caught up to each others changes does the document stabilize and you can talk about authoritative current contents of the file.
This model may sound exotic and not appropriate for editing local files, and it may not be. But the underlying assumptions of those models, that what you’re seeing may not reflect the current contents of the file and that those contents may change at any time, are good assumptions to make even for local file editors. The next part is about how to make an editor work under those assumptions.
OT
How do online collaborative tools work then? The ones I’m familiar with use operational transformation, or OT. The way OT works is by changing the focus from the question what are the contents of this file? to what operations have been performed on the contents of this file? This slight change in viewpoint makes a huge difference.
In a (very simplified) non-OT model your interaction with a source file in an editor works something like this:
-
When a file is opened, read the current contents into a buffer.
-
Any changes the user makes are applied directly (destructively) to the buffer.
-
When user asks for the file to be saved the current contents of the buffer are written directly into the file. If the file has changed those changes would be lost so throw up a revert/override dialog and let the user choose.
In the OT model the interaction would work something along these lines. (This is a very rough outline, a proper OT model would be much cleaner than this makes it sound):
-
When a file is opened, read the current contents into a buffer.
-
Any changes the user makes are stored as operations, essentially a diff against the original file contents.
-
When the user asks the editor to save the file it does the following:
-
Read the current contents of the file.
-
Generate a three-way diff between the original contents, the current contents, and the pending operations.
-
Apply the resulting diff to the current file contents.
-
Save the results.
-
While this isn’t completely accurate it gives a sense of the basics: what you’re doing is not editing a file, though it looks just like it, you’re building a set of changes against the file contents from one point in time. The changes you build may be applied to the original file contents, or they may be applied to a different version if the file changes. This model is much more robust to the way people actually work with source code. And though you may not always want your editor to merge changes on the fly when you save wouldn’t it be nice if it would at least give you the option?
Beyond just saving this model has several other nice properties. When the system notices that a file has changed, even before you want to save it, it can update your buffer by doing essentially the same as when saving except that instead of applying your pending changes to the current file contents it would apply the changes between the old and current file contents to the buffer containing your pending changes. It also allows you to undo saving since saving is equivalent to applying a diff and you can undo that, even when there’s been subsequent changes, just by reverting the diff.
There are probably numerous other solutions to this issue. I’m most familiar with OT because I worked with when I was on the wave project and I know it works extremely well. (I wish I had a good place to point anyone interested in learning the basics but I don’t, only the wikipedia page listed above). My main point is that this issue should be solved somehow, and it’s a problem that’s been solved in other contexts. I think it’s about time those solutions make their way to desktop editors.